Top 7 Best Online Feature Engineering Courses

Are you wondering which remote classroom to attend? You have spare time and want to broaden your horizon about a specific field of study whilst just staying at ... read more...home. Thus, to satisfy the burgeoning demand for online yet qualifying courses, Toplist has compiled a rundown of the Best Online Feature Engineering Courses offered by the famous companies, top organizations, and knowledgeable instructors across the globe for those who are in need!
-
Want to know about Vertex AI Feature Store? Want to know how you can improve the accuracy of your ML models? What about how to find which data columns make the most useful features? Welcome to Feature Engineering on Google Cloud, one of the best online feature engineering courses. It is to discuss good versus bad features and how you can preprocess and transform them for optimal use in your models. This course includes content and labs on feature engineering using BigQuery ML, Keras, and TensorFlow.
Feature Engineering on Google Cloud can be applied to several Specialization or Professional Certificate programs. When you successfully complete this course, it will count towards your training in one of the following programs: Number of Google Cloud Certification Prep: Machine Learning Engineer Professional Certificate and Machine Learning on Google Cloud SpecializationYou will learn:
- Use the Vertex AI Feature Store
- Describe how to move from raw data to features
- Perform Feature Engineering in BigQuery ML and Keras
- Preprocess features using Apache Beam and Cloud Data Flow
This course offers:
- Flexible deadlines: Reset deadlines based on your availability.
- Certificate: Get a Certificate upon completion
- 100% online
- Intermediate level
- Approximately 2 hours to complete
- Subtitles: English
Coursera Rating: 4.5/5
Enroll here: https://www.coursera.org/learn/feature-engineering

coursera.org 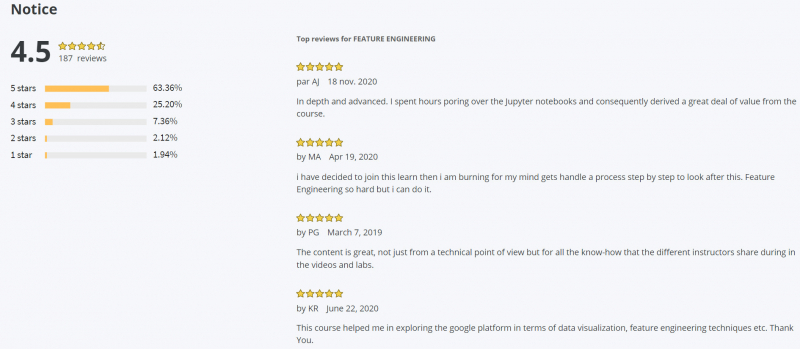
coursera.org - Use the Vertex AI Feature Store
-
Feature Engineering and Bias Detection are among the best online feature engineering courses. This is the third course in the IBM AI Enterprise Workflow Certification specialization. You are strongly encouraged to complete these courses in order as they are not individual independent courses, but part of a workflow where each course builds on the previous ones.
Feature Engineering and Bias Detection introduce you to the next stage of the workflow for our hypothetical media company. In this stage of work, you will learn best practices for feature engineering, handling class imbalances, and detecting bias in the data. Class imbalances can seriously affect the validity of your machine learning models, and the mitigation of bias in data is essential to reducing the risk associated with biased models. These topics will be followed by sections on best practices for dimension reduction, outlier detection, and unsupervised learning techniques for finding patterns in your data. The case studies will focus on topic modeling and data visualization.
By the end of this course you will be able to:
- Employ the tools that help address class and class imbalance issues
- Explain the ethical considerations regarding bias in data
- Employ ai Fairness 360 open source libraries to detect bias in models
- Employ dimension reduction techniques for both EDA and transformations stages
- Describe topic modeling techniques in natural language processing
- Employ outlier detection algorithms as a quality assurance tool and a modeling tool
- Employ unsupervised learning techniques using pipelines as part of the AI workflow
This course offers:
- Flexible deadlines: Reset deadlines based on your availability.
- Get a Certificate when you complete
- 100% online
- Course 3 of 6 in the IBM AI Enterprise Workflow Specialization
- Advanced level
- Approximately 12 hours to complete
- Subtitles: English
Coursera Rating: 4.4/5
Enroll here: https://www.coursera.org/learn/ibm-ai-workflow-feature-engineering-bias-detection

coursera.org 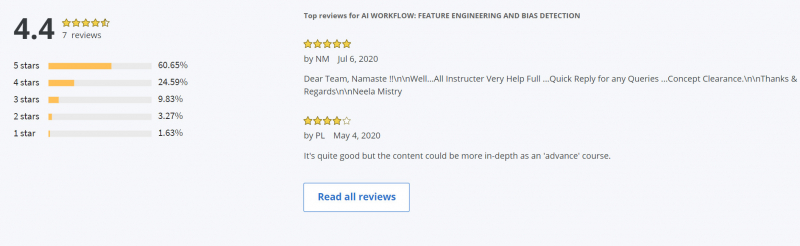
coursera.org -
Another best online feature engineering course is Data Processing and Feature Engineering with MATLAB. In this course, you will build on the skills learned in Exploratory Data Analysis with MATLAB to lay the foundation required for predictive modeling. This intermediate-level course is useful to anyone who needs to combine data from multiple sources or times and has an interest in modeling. These skills are valuable for those who have domain knowledge and some exposure to computational tools, but no programming background. To be successful in this course, you should have some background in basic statistics (histograms, averages, standard deviation, curve fitting, interpolation) and have completed Exploratory Data Analysis with MATLAB.
Throughout Data Processing and Feature Engineering with MATLAB course, you will merge data from different data sets and handle common scenarios, such as missing data. In the last module of the course, you will explore special techniques for handling textual, audio, and image data, which are common in data science and more advanced modeling. By the end of this course, you will learn how to visualize your data, clean it up and arrange it for analysis, and identify the qualities necessary to answer your questions. You will be able to visualize the distribution of your data and use visual inspection to address artifacts that affect accurate modeling.
This course offers:
- Flexible deadlines: Reset deadlines based on your availability.
- Get a Certificate when you complete
- 100% online
- Course 2 of 4 in the Practical Data Science with MATLAB Specialization
- Intermediate level
- Approximately 20 hours to complete
- Subtitles: Arabic, French, Portuguese (European), Italian, Vietnamese, German, Russian, English, Spanish
Coursera Rating: 4.7/5
Enroll here: https://www.coursera.org/learn/feature-engineering-matlab

coursera.org 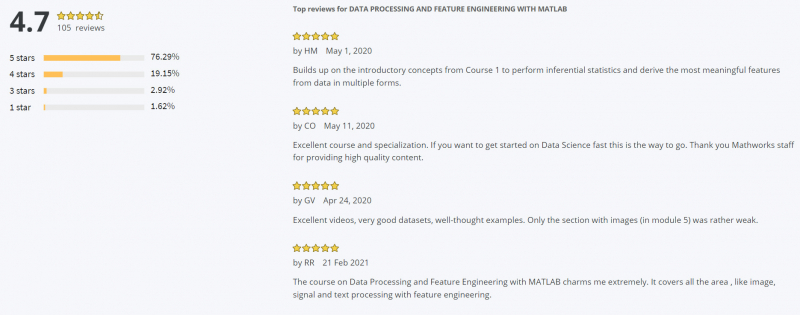
coursera.org -
Welcome to Feature Engineering for Machine Learning, the most comprehensive course on feature engineering available online. In this course, you will first learn the most popular and widely used techniques for variable engineering, like mean and median imputation, one-hot encoding, transformation with logarithm, and discretization. Then, you will discover more advanced methods that capture information while encoding or transforming your variables to improve the performance of machine learning models. You will learn methods like the weight of evidence, used in finance, and how to create monotonic relationships between variables and targets to boost the performance of linear models. You will also learn how to create features from the date and time variables and how to handle categorical variables with a lot of categories.
The methods that you will learn were described in scientific articles, are used in data science competitions, and are commonly utilized in organizations. And what’s more, they can be easily implemented by utilizing Python's open-source libraries! Throughout the lectures, you’ll find detailed explanations of each technique and a discussion about their advantages, limitations, and underlying assumptions, followed by the best programming practices to implement them in Python. By the end of the course, you will be able to decide which feature engineering technique you need based on the variable characteristics and the models you wish to train. And you will also be well placed to test various transformation methods and let your models decide which ones work best.
This course offers:
- Flexible deadlines: Reset deadlines based on your availability.
- Get a Certificate when you complete
- 100% online
- Advanced level
- Approximately 10.5 hours to complete
- Subtitles: English
Udemy Rating: 4.7/5
Enroll here: https://www.udemy.com/course/feature-engineering-for-machine-learning/

udemy.com 
udemy.com -
Real-life data is unclear. This is the reason why preprocessing tasks take approximately 70% of the time in the ML modeling process. Moreover, there is a lack of dedicated courses which deal with this challenging task. Introducing, "Data Science Course: Data Cleaning & Feature Engineering" a hardcore completely dedicated course to the most difficult tasks of Machine Learning modeling - "Data preprocessing". If you want to enhance your data preprocessing skills to get better high-performing ML models, then this course is for you!
This course has been designed by experienced Data Scientists who will help you to understand the whys and hows of preprocessing. You will be guided step-by-step into the process of data preprocessing. With every tutorial, you will develop new skills and improve your understanding of preprocessing challenging ways to overcome this challenge.In this course, you will learn:
- Preprocessing the data takes 60%-70% of the time. The course provides the entire toolbox to you to convert your raw data to model ready data
- Become efficient in pre-processing data using various python packages such as pandas_profiling, category-encoders, etc.
- Learn Scikit-learn Pipeline, Column transformers to make the code readable and efficient
- Export Analysis Output to a Text file or Excel (export multiple data frames to different sheets and multiple data frames to the same sheet in a workbook programmatically.
- Become an Expert in Python Pandas and scikit-learn for data manipulation and feature engineering
This course offers:
- Flexible deadlines: Reset deadlines based on your availability.
- Get a Certificate when you complete
- 100% online
- Advanced level
- Approximately 6 hours to complete
- Subtitles: English
Udemy Rating: 4.7/5
Enroll here: https://www.udemy.com/course/data-science-course-data-cleaning-feature-engineering/

udemy.com 
udemy.com -
Every day you read about the amazing breakthroughs in how the newest applications of machine learning are changing the world. Often this reporting glosses over the fact that a huge amount of data munging and feature engineering must be done before any of these fancy models can be used. In Feature Engineering for Machine Learning in Python course, you will learn how to do just that. You will work with Stack Overflow Developers survey, and historic US presidential inauguration addresses, to understand how best to preprocess and engineer features from categorical, continuous, and unstructured data. This course will give you hands-on experience on how to prepare any data for your own machine learning models.
In Feature Engineering for Machine Learning in Python course, you will explore what feature engineering is and how to get started with applying it to real-world data. You will be introduced to the reality of messy and incomplete data. You will learn how to find where your data has missing values and explore multiple approaches on how to deal with them. Besides, you will focus on analyzing the underlying distribution of your data and whether it will impact your machine learning pipeline. You will learn how to deal with skewed data and situations where outliers may be negatively impacting your analysis.
This course offers:
- Flexible deadlines: Reset deadlines based on your availability.
- Get a Certificate when you complete
- 100% online
- Intermediate level
- This course is part of these tracks: Machine Learning Scientist with Python
- Approximately 4 hours to complete
- Subtitles: English
Enroll here: https://app.datacamp.com/learn/courses/feature-engineering-for-machine-learning-in-python

app.datacamp.com 
app.datacamp.com -
Feature Engineering with PySpark is also one of the best online feature engineering courses. This is another feature engineering course by Datacamp. The real world is messy and your job is to make sense of it. Toy datasets like MTCars and Iris are the result of careful curation and cleaning, even so, the data needs to be transformed for it to be useful for powerful machine learning algorithms to extract meaning, forecast, classify, or cluster. This course will cover the gritty details that data scientists are spending 70-80% of their time on; data wrangling and feature engineering. With the size of datasets now becoming ever larger, let's use PySpark to cut this Big Data problem down to size!
In this course, you will learn how to prepare and clean data and how to create new features for your machine learning model. Then you will learn how to build a machine learning model and how to evaluate the model.
This course offers:
- Flexible deadlines: Reset deadlines based on your availability.
- Get a Certificate when you complete
- 100% online
- Intermediate level
- This course is part of these tracks: Big Data with PySpark
- Approximately 4 hours to complete
- Subtitles: English
Enroll here: https://app.datacamp.com/learn/courses/feature-engineering-with-pyspark

app.datacamp.com 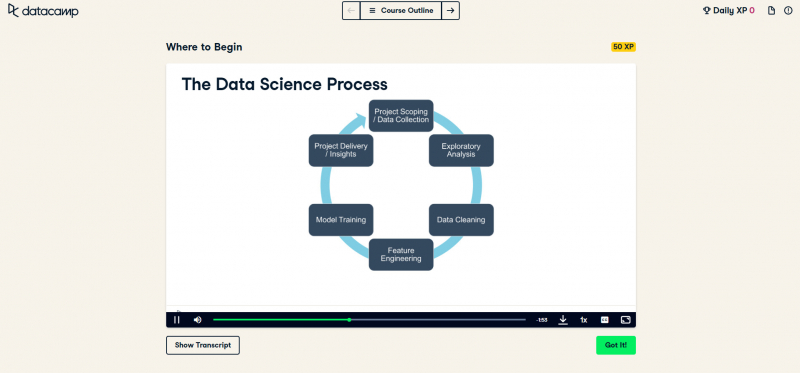
app.datacamp.com