Top 10 Best Online Logistic Regression Courses

It is extremely difficult for students with so many Logistic Regression courses to meet their needs. Learners often ask whether for each case there is a ... read more...Logistic Regression course. The reply is YES. Popular courses are available below. Registration for the right course is a vital factor for your career advancement. Based on your choice, choose one that best suits your needs. However, let’s take a look at the best online Logistic Regression courses
-
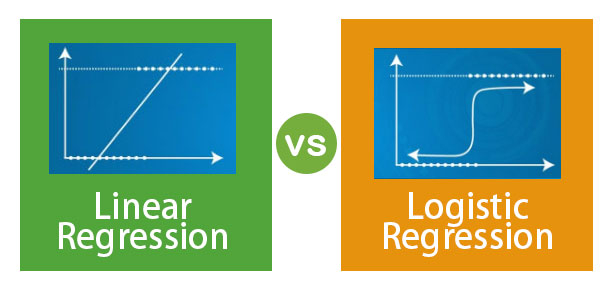
Why did you choose logistic regression for public health over just logistic regression? Every data set has its own set of issues, and public health data sets have unique characteristics that require specific attention. In a nutshell, they're a shambles. This is a hands-on course, like the others in the series, that will give you plenty of practice with R on real-life, messy data, with the worked example for this course being predicting who has diabetes based on a set of patient characteristics. Furthermore, the interpretation of the regression model's outputs varies depending on the viewpoint, and public health must consider not just the viewpoint of an individual patient but also the viewpoint of the entire population. However, because much of what is presented in this course applies to logistic regression in any data set, you will be able to apply the ideas of this course to logistic regression in a broader sense.
You will be able to do the following by the end of this course: When is it appropriate to apply logistic regression?; Define the terms "odds" and "odds ratios."; Interpret the results of simple and multiple logistic regression analyses with R; In R, evaluate the multiple logistic regression model assumptions; Describe and contrast a few popular approaches to selecting a multiple regression model.
This course builds on skills learned in the previous two courses of the Statistics for Public Health specialty, such as hypothesis testing, p values, and how to use R. Before commencing this course, they recommend that you examine Statistical Thinking for Public Health and Linear Regression for Public Health if you are unfamiliar with these abilities. If you already know how to do these things, they were confident you'll appreciate learning more about them in Statistics for Public Health: Logistic Regression for Public Health. They hope you have a good time on the courses
LEARN STEP BY STEP:
- Describe a data set from scratch using descriptive statistics and simple graphical methods as a first step for advanced analysis using R software
- Interpret the output from your analysis and appraise the role of chance and bias as potential explanations
- Run multiple logistic regression analysis in R and interpret the output
- Evaluate the model assumptions for multiple logistic regression in R
Rating: 4.8/5
Enroll here: coursera.org/learn/logistic-regression-r-public-health
publichealthnotes.com 
youtube.com -
They will utilize visualizations to guide machine learning workflow in this course. Based on passive sensor data such as temperature, humidity, light, and CO2 levels, they will attempt to forecast whether rooms in flats are inhabited or vacant. For binary classification, they will create a logistic regression model. This is a follow-up to the Room Occupancy Detection course. They will cover the following topics in machine learning workflow, with an emphasis on visual steering of analysis: model evaluation with ROC/AUC plots, confusion matrices, cross-validation scores, and defining discrimination thresholds for logistic regression models.
This course uses Rhyme, Coursera's hands-on project platform. Rhyme allows you to work on projects in your browser in a hands-on manner. You'll have immediate access to pre-configured cloud PCs with all of the applications and data you'll need for the job. Everything is fully set up in your browser, so you can concentrate solely on learning. You'll get immediate access to a cloud desktop with Python, Jupyter, Yellowbrick, and scikit-learn pre-installed for this project.
Notes:
- You will have 5 attempts to access the cloud desktop. You will, however, be allowed to watch the instructional films as many times as you like.
- Learners in the North American region will benefit the most from this course. They were working on bringing the same experience to other parts of the world.
THE SKILLS YOU WILL DEVELOP
- Data science
- Machine-learning
- Python Programming
- Data Visualization (DataViz)
- Scikit-Learn
LEARN STEP BY STEP:
- ROC/AUC Plots
- Classification Report and Confusion Matrix
- Cross Validation Scores
- Evaluating Class Balance
- Discrimination Threshold for Logistic Regression
Rating: 4.8/5
Enroll here: coursera.org/projects/machine-learning-model-yellowbrick

coursera.org 
medium.com -
Another excellent platform for studying Online Logistic Regression Courses is Classification. This course exposes you to one of the most common supervised Machine Learning modeling families: classification. You'll learn how to utilize error metrics to compare models and how to train predictive models to identify categorical outcomes. This course's hands-on component focuses on using recommended practices for classification, such as train and test splits, and dealing with data sets with unbalanced classes
You should be able to do the following by the end of this course:
- Different categorization and classification ensembles uses and applications
- Explain logistic regression models and how to utilize them.
- Explain decision trees and tree-ensemble models and how to use them.
- Explain and apply alternative classification ensemble approaches.
- Compare and pick the categorization model that best fits your data using a number of error metrics.
- To address unbalanced classes in a data set, use oversampling and undersampling approaches.
Who should enroll in this class?
This course is for aspiring data scientists who want to obtain hands-on experience in a corporate setting with Supervised Machine Learning Classification algorithms.
What abilities should you possess?
You should be familiar with Python programming and have a basic understanding of Data Cleaning, Exploratory Data Analysis, Calculus, Linear Algebra, probability, and Statistics in order to get the most out of this course.
THE SKILLS YOU WILL DEVELOP:
- Decision Tree
- Learning set
- Classification Algorithms
- Supervised Learning
- Machine Learning (ML) Algorithms
Rating: 4.8/5
Enroll here: coursera.org/learn/supervised-machine-learning-classification
javatpoint.com 
la.mathworks.com -
There are statistics all over the place. There's a good chance it'll rain today. Unemployment rate trends over time. India's chances of winning the next Cricket World Cup. Football, for example, began as a bit of fun but has since developed into a large business. In medicine, statistical analysis plays an important role, not least in the wide and basic field of public health.
This specialism will provide you an overview of medical research and how – and why – you can turn a hazy idea into a scientifically testable hypothesis. You'll learn about sampling, uncertainty, variation, missing values, and distributions, among other statistical concepts. Then, using R, one of the most widely used and versatile free software packages around, you'll get your hands dirty analyzing data sets covering some major public health issues, such as fruit and vegetable consumption and cancer, diabetes risk factors, and predictors of death following heart failure hospitalization.
This specialism consists of four courses – statistical reasoning, linear regression, logistic regression, and survival analysis – and will be offered as part of future Global Master in Public Health program, which will begin in September 2019. The speciality can be pursued independently of the GMPH and requires no prior understanding of statistics or the R programming language. All you need is an interest in medical issues as well as quantitative data.
Applied Learning Project:
Each course Specialization Statistical Analysis with R will present essential ideas as well as a data collection that will be used as a working example throughout the course. Missing numbers and strange distributions are all too typical in public health data. Real or simulated data from real patient-level data sets will be used (all anonymised and with usage permissions in place).
As you encounter typical data and analytical issues to solve and debate with your other learners, the emphasis will be on "learning through doing" and "learning through discovering." Before accessing the answers and explanations offered by the teachers, you'll have the opportunity to sort things out for yourself and with your peers.
LEARN STEP BY STEP:
- Recognise the key components of statistical thinking in order to defend the critical role of statistics in modern public health research and practice
- Describe a given data set from scratch using descriptive statistics and graphical methods as a first step for more advanced analysis using R software
- Apply appropriate methods in order to formulate and examine statistical associations between variables within a data set in R
- Interpret the output from your analysis and appraise the role of chance and bias as explanations for your results
Rating: 4.7/5
Enroll here: coursera.org/specializations/statistical-analysis-r-public-health

classcentral.com -
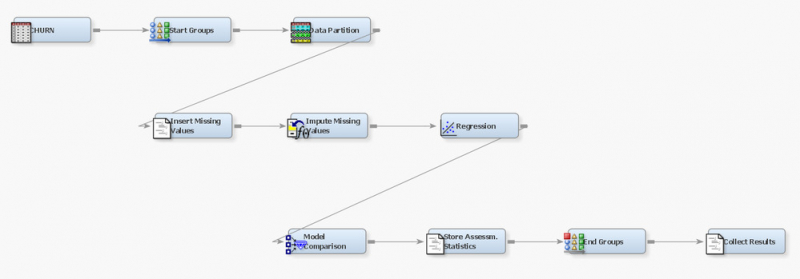
Predictive modeling with SAS/STAT software is covered in this course, with a focus on the LOGISTIC process. Selecting variables and interactions, recoding categorical variables based on the smooth weight of evidence, analyzing models, addressing missing values, and employing efficiency strategies for big data sets are all covered in this course.
Find out how to: To model an individual's behavior as a function of known inputs, use logistic regression, Using ODS Statistical Graphics, create effect plots and odds ratio graphs, Handle data values that are missing, Multicollinearity in your predictors should be addressed, Model performance is evaluated, and models are compared.
THE SKILLS YOU WILL DEVELOP:
- Oversampling
- Logistic Regression
- Predictive Modeling
- regression
Rating: 4.6/5
Enroll here: coursera.org/learn/sas-predictive-modeling-using-logistic-regression
communities.sas.com -
You will learn to develop a logistic regression model using Pyspark MLLIB to categorize patients as diabetes or non-diabetic in this one-hour project-based course. The popular Pima Indian Diabetes data set will be used. Goal is to classify diabetes using a basic logistic regression classifier from the pyspark Machine learning toolkit. With the installation of Pyspark, they will be able to complete the entire project on the Google Colab environment. To accomplish this project, you'll need a free Gmail account. Please keep in mind that the dataset and model used in this project cannot be used in real-life situations. They solely use your information for educational purposes.
You will be able to develop a logistic regression classifier using Pyspark MLlib to categorize diabetic and nondiabetic patients by the end of this project. You'll be able to use Pyspark in the Google colab environment as well. You will be able to clean and prepare data for analysis as well. You should be familiar with the Python programming language as well as the Logistic Regression algorithm on a theoretical level. To accomplish this project, you'll need a free Gmail account.
Note: This course is best suited to students in the North American region. They were working on bringing the same experience to other parts of the world.THE SKILLS YOU WILL DEVELOP
- Data science
- Machine-learning
- Python Programming
- Google colab
- PySpark
LEARN STEP BY STEP:
- Introduction & Install Dependencies
- Clone and Explore Dataset
- Data Cleaning and Preparation
- Correlation analysis and Feature Selection
- Split Dataset and Build the Logistic Regression Model
- Evaluate and Save the model
- Model Prediction on a new set of unlabeled data
Rating: 4.6/5
Enroll here: coursera.org/projects/diabetes-prediction-with-pyspark-mllib
github.com -
Enroll hereIn the Natural Language Processing with Classification and Vector Spaces, one of the best online logistic regression courses, is first courses, you will: Use logistic regression and then nave Bayes to analyze the sentiment of tweets, Use vector space models to discover relationships between words and then use PCA to reduce the dimensionality of the vector space and visualize those relationships, Write a simple English to French translation algorithm that uses pre-computed word embeddings and locality-sensitive hashing to relate words via approximate k-nearest neighbor search.
You'll have produced NLP apps that conduct question-answering and sentiment analysis, created tools to translate languages and summarize text, and even built a chatbot by the end of this Specialization! Two experts in natural language processing, machine learning, and deep learning devised and taught this Specialization. Younes Bensouda Mourri is a Stanford University AI Instructor who also assisted in the development of the Deep Learning Specialization. ukasz Kaiser is a Google Brain Staff Research Scientist and co-author of Tensorflow, the Tensor2Tensor and Trax libraries, as well as the Transformer paper.
LEARN STEP BY STEP:
- Use logistic regression, naïve Bayes, and word vectors to implement sentiment analysis, complete analogies & translate words.
Rating: 4.6/5
Enroll here: coursera.org/learn/classification-vector-spaces-in-nlp
stoodnt.com 
analyticsvidhya.com -
Welcome to the Logistic with NumPy and Python project-based course. You will accomplish all of the machine learning in this project without utilizing any of the popular machine learning libraries like scikit-learn or statsmodels. The goal of this project is for you to implement all of the machinery of the various learning algorithms yourself, including gradient descent, cost function, and logistic regression, so you may gain a better knowledge of the principles. You will be able to design a logistic regression model using Python and NumPy, do basic exploratory data analysis, and develop gradient descent from scratch after completing this project. Prior Python programming skills and a basic understanding of machine learning theory are required for this project.
This course uses Rhyme, Coursera's hands-on project platform. Rhyme allows you to work on projects in your browser in a hands-on manner. You'll have immediate access to pre-configured cloud PCs with all of the applications and data you'll need for the job. Everything is fully set up in your browser, so you can concentrate solely on learning. You'll gain immediate access to a cloud desktop with Python, Jupyter, NumPy, and Seaborn pre-installed for this project
THE SKILLS YOU WILL DEVELOP
- Data science
- Machine-learning
- Python Programming
- Classification
- Numpy
LEARN STEP BY STEP:
- Introduction and Project Overview
- Load the Data and Import Libraries
- Visualize the Data
- Define the Logistic Sigmoid Function
- Compute the Cost Function and Gradient
- Cost and Gradient at Initialization
- Implement Gradient Descent
- Plotting the Convergence of
- Plotting the Decision Boundary
- Predictions Using the Optimized Values
Rating: 4.5/5
Enroll here: coursera.org/projects/logistic-regression-numpy-python

coursera.org 
nablasquared.com -
They will broaden understanding of statistical inference techniques in this course by concentrating on the science and art of fitting statistical models to data. They will expand on the ideas offered in the Statistical Inference course (Course 2) to stress the relevance of linking research topics to data analysis methodologies. They will also look at a variety of modeling goals, including as inferring connections between variables and making predictions for future data. This course will cover linear regression, logistic regression, extended linear models, hierarchical and mixed effects (or multilevel) models, and Bayesian inference approaches, among other statistical modeling techniques.
The course will stress alternative modeling methodologies for different types of data sets, based on the research design underlying the data (referring back to Course 1, Understanding and Visualizing Data with Python). Learners will go through tutorials concentrating on specific case studies during these lab-based sessions to help consolidate the week's statistical ideas, which will include deeper dives into Python libraries such as Statsmodels, Pandas, and Seaborn. This course makes use of Coursera's Jupyter Notebook platform.
THE SKILLS YOU WILL DEVELOP:
- Bayesian Statistics
- Python Programming
- Statistical Model
- Statistical regression
Rating: 4.4/5
Enroll here: coursera.org/learn/fitting-statistical-models-data-python

coursera.org 
corporatefinanceinstitute.com -
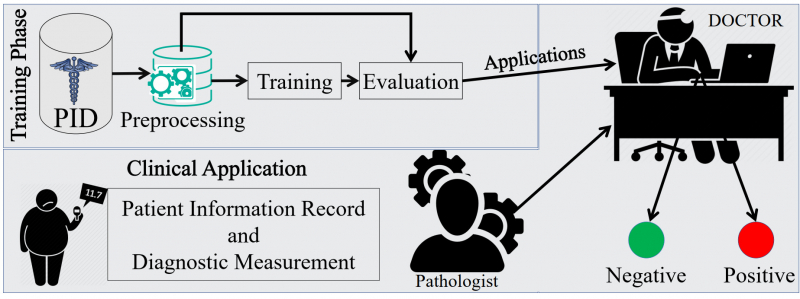
This 2-hour project-based course will teach you how to use Scikit-learn to create a Logistic regression model to classify breast cancer as Malignant or Benign. The Breast Cancer Wisconsin (Diagnostic) Data Set from Kaggle will be used. Objective is to classify cancer using a basic logistic regression classifier. The entire project will be completed in the Google Colab environment. To accomplish this project, you'll need a free Gmail account.
Please keep in mind that the dataset and model used in this project cannot be used in real-life situations. This information is solely used for instructional reasons. You will be able to construct a logistic regression classifier to distinguish between malignant and noncancerous patients at the conclusion of this project. You'll be able to set up and use the Google colab environment as well. You will be able to clean and prepare data for analysis as well. You should be familiar with the Python programming language as well as the Logistic Regression technique on a theoretical level. To accomplish this project, you'll need a free Gmail account.
Note: This course is best suited to students in the North American area. They were working on bringing the same experience to other parts of the world.
THE SKILLS YOU WILL DEVELOP:
- Python Programming
- Cancer prediction
- Machine Learning
- Data Mining
LEARN STEP BY STEP:
- Introduction and Import Libraries
- Download dataset directly from Kaggle
- Load & Explore the Dataset
- Perform LabelEncoding
- Split the data into Independent and Dependent sets and perform Feature Scaling
- Building Logistic Regression Classifier
- Evaluate the performance of the model
Rating: 4.2/5
Enroll here: coursera.org/projects/breast-cancer-prediction-using-machine-learning
kaggle.com